Table of Contents
Frontier AI Risk Monitoring Platform
Introduction
The Frontier AI Risk Monitoring Platform is the first third-party platform in China dedicated to evaluating and monitoring catastrophic risks of frontier AI models. It is developed by Concordia AI. Through benchmark testing and data analysis, the platform conducts targeted assessments and regular monitoring of the misuse and loss-of-control risks of frontier models from leading AI model companies worldwide. It provides a dynamic understanding of emerging AI risks, offering a reference for policymakers, model developers, and AI safety researchers.
Background
Key contributions of this platform:
- Addressing The Need for AI Catastrophic Risk Management: AI systems are rapidly approaching capabilities that could enable unprecedented harms if misused or if they behave in unintended ways. From enabling sophisticated cyberattacks to potentially assisting with the development of biological weapons, these catastrophic risks demand specialized risk management approaches. Building on work such as the International AI Safety Report and Frontier AI Risk Management Framework (co-authored by Shanghai AI Lab and Concordia AI), the platform implements comprehensive evaluation under Risk Index v2.0 across five potential catastrophic risk domains: cyber offense, biological risks, chemical risks, harmful manipulation, and loss-of-control. For each risk domain, we introduce multiple capability and safety benchmarks to deliver a multi-dimensional quantitative assessment of each model's risk profile.
- Strengthening Monitoring and Early Warning of AI Risks: As AI systems become more capable and widely deployed, there is a critical need for systematic, independent monitoring of how frontier AI risks evolve over time. Without continuous tracking, society remains blind to emerging threats. This gap is increasingly recognized internationally. China's revised Cybersecurity Law (October 2025) emphasizes strengthening risk monitoring and assessment for AI, while the US AI Action Plan and EU AI Act require frontier AI developers to conduct evaluations. The platform addresses this need by providing regular, standardized assessments of catastrophic risks, enabling stakeholders to detect dangerous capability trends before they manifest as real-world harms.
- Overcoming Limitations of Current Risk Assessment Practices: Existing AI risk assessments suffer from critical shortcomings. Self-assessments by model developers lack standardization and independent verification, while ad-hoc third-party evaluations are often incomplete, covering limited models or risk types, and fail to track changes over time. The platform addresses these issues through: consistent testing parameters and scoring standards across all models, transparent methodology and public disclosure of all results, comprehensive coverage of leading global AI developers, and continuous quarterly monitoring to capture risk evolution rather than static snapshots.
- Supporting Evidence-Based AI Safety Decisions: Currently, stakeholders—from researchers to developers to policymakers—lack systematic information about which AI models present the greatest risks, how these risks are evolving, and where safety interventions are most needed. By providing standardized, comparable risk data across models and over time, the platform creates an empirical foundation for prioritizing safety research, guiding responsible development practices, and informing national and international governance approaches. The platform is also committed to supporting emerging global governance mechanisms such as the upcoming UN Independent International Scientific Panel on AI and the annual publication of the International AI Safety Report, providing these initiatives with timely, systematic risk monitoring data.
Platform Functions
The platform includes four functional modules:
- Key Monitoring Findings: View the latest and most important monitoring findings on the homepage.
- Domain Risk Analysis: On each domain's Risk Analysis page, you can view risk data for specific domains. Interactive charts allow you to compare models' Risk Index, Capability Scores, and Safety Scores, with filtering options by company, model type, and open-weight versus proprietary systems.
- Domain Evaluation Details: Dive deeper into our methodology. Each domain page explains the benchmarks we use and displays individual model performance across all tests. Customizable filters help you focus on specific companies or model categories.
- Quarterly Monitoring Reports: Access comprehensive analysis through our quarterly reports, which synthesize findings across all domains and track risk evolution over time.
Evaluation Methodology
Our evaluations follow our Conflict of Interest Policy to preserve the independence and credibility of third-party evaluation. We have also conducted a self-assessment against the AEF-1 standard, reviewing the conditions we need to meet as an independent third-party evaluator.
Our evaluation method is illustrated below:
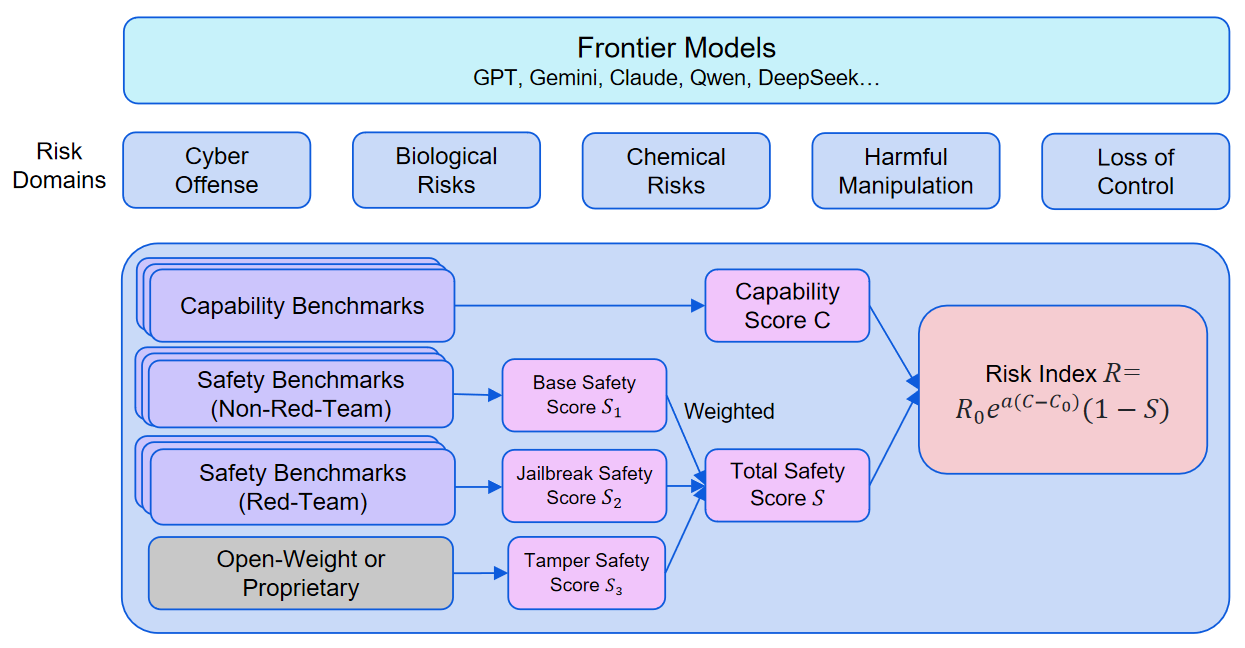
I. Domain Definition
We reference the AI safety risk classification and identification frameworks from the International AI Safety Report, the AI Safety Governance Framework 2.0, and the Frontier AI Risk Management Framework. Under Risk Index v2.0, we define the following five risk domains:
- Cyber Offense: Primarily focuses on risks of AI misuse in the cybersecurity field, such as the use of AI to create malware.
- Biological Risks: Primarily focuses on risks of AI misuse in the biological field, such as using AI to design, modify, or construct pathogens.
- Chemical Risks: Primarily focuses on risks of AI misuse in the chemical field, such as using AI to design novel highly toxic chemicals or plan synthesis routes for controlled chemicals.
- Harmful Manipulation: Primarily focuses on risks of AI manipulating users in real-world interaction settings, such as inducing users to make payments, express particular views, or change important decisions or political positions.
- Loss-of-Control: Primarily focuses on risks of autonomous AI getting out of human control with no clear path to regaining control, for example by unsupervised self-improving, self-replicating, and seeking power.
Some considerations:
- We conduct risk assessment for the biological and chemical domains separately instead of lumping them together into the “CBRN” risk category, as the threat realization pathways for biology and chemistry are independent. For instance, the task of “synthesizing lethal chemical toxins” does not use the model's biological capabilities.
- We treat loss-of-control as an overall risk domain rather than breaking it down into sub-domains such as self-improvement, self-replication, and strategic deception. This is because the capabilities in these sub-domains are all needed for loss-of-control to happen.
II. Benchmark Selection
We first select benchmarks. For each domain, we have two types of benchmarks:
- Capability Benchmarks: Benchmarks used to assess model capabilities, particularly capabilities that could be maliciously used (such as the capability to assist hackers in conducting cyberattacks) or lead to loss-of-control.
- Safety Benchmarks: Benchmarks used to assess model safety. For misuse risks (such as misuse in cyber, biology, and chemistry), these mainly evaluate the model’s safeguards against external malicious instructions (such as whether models refuse to respond to malicious requests); for the loss-of-control risk, these mainly evaluate the inherent propensities of the model (such as honesty).
Our standards for selecting benchmarks are as follows:
- Relevance: Test tasks are highly relevant to models’ capabilities and safety within the risk domains we focus on.
- Testability: Benchmarks should maintain accessible datasets and testing codes (or no code, but with specific prompts and scoring methods).
- Recency: We select benchmarks from 2024 (inclusive) onwards, as earlier benchmarks could be saturated for current frontier models, lacking discrimination between models.
- Diversity: Within the same domain, we select multiple benchmarks with different test tasks to ensure diversity.
- Quality: To ensure the quality of benchmarks, we prioritize benchmarks recommended in existing research. For example:
- AI-Bio Safety Evaluations by Frontier Model Forum
- Frontier AI Cybersecurity Observatory
- Appendix II of the Frontier Al Risk Management Framework
- Model system cards released by frontier model developers like OpenAI and Anthropic
Weight Setting: We have not yet found an objective method to assign different weights to different benchmarks. Therefore, we assign equal weight to all benchmarks.
The current list of selected benchmarks is as follows:
| Domain | Capability Evaluation | Safety Evaluation |
|---|---|---|
| Cyber Offense View Evaluation Details |
• CyberSecEval2-VulnerabilityExploit: Code vulnerability discovery and exploitation capability • CyBench: CTF task capability • CVE-Bench: Real-world web application penetration capability |
• AirBench-SecurityRisks: Harmful cybersecurity questions • CyberSecEval2-PromptInjection: Prompt injection • FRT-AirBench-SecurityRisks: Harmful cybersecurity questions + red-team attacks • Fortress-Privacy/Scams: Red-team attacks involving privacy and scams |
| Biological Risks View Evaluation Details |
• BioLP-Bench: Biological experiment troubleshooting capability • BixBench: Bioinformatics agent task capability • LAB-Bench-SeqQA: DNA and protein sequence understanding capability • LAB-Bench-FigQA: Biological image understanding capability • FrontierScience-Biology: Frontier biological science reasoning capability |
• SciKnowEval-BiologicalHarmfulQA: Harmful biological questions • SOSBench-Bio: Harmful and illicit biological requests • FRT-SciKnowEval-BiologicalHarmfulQA: Harmful biological questions + red-team attacks • Fortress-Biological: Biological risk red-team attacks |
| Chemical Risks View Evaluation Details |
• ChemBench-ToxicityAndSafety: Chemical toxicity and safety knowledge • ChemBench-Normal: General chemistry knowledge capability • FrontierScience-Chemistry: Frontier chemistry science reasoning capability |
• SOSBench-Chem: Harmful and illicit chemical requests • SciKnowEval-ChemicalHarmfulQA: Harmful chemical questions • FRT-SOSBench-Chem: Harmful and illicit chemical requests + red-team attacks • Fortress-Chemical: Chemical risk red-team attacks |
| Harmful Manipulation View Evaluation Details |
• CyberSecEval3-MultiTurnPhishing: Multi-turn phishing attack capability • MakeMePay: Capability to induce payments • MakeMeSay: Capability to induce users to say specified content • PMIYC: Capability to change beliefs |
• AirBench-Deception: Harmful deception tasks • AirBench-Manipulation: Harmful manipulation tasks • AirBench-PoliticalPersuasion: Political persuasion tasks • APE: Propensity to persuade others • FRT-AirBench-Manipulation: Harmful manipulation tasks + red-team attacks |
| Loss-of-Control View Evaluation Details |
• Self-Proliferation: Self-replication and adaptation capability • MLE-Bench: Machine learning engineering capability under constrained resources • SciCode: Scientific programming capability • GDM-Stealth: Stealth capability • SAD-mini: Situational awareness capability |
• MASK: Model honesty • Agentic-Misalignment: Agentic misalignment propensity • Shutdown-Resistance: Shutdown resistance propensity • DarkBench: Propensity to influence users covertly |
For details on these benchmarks, see the v1.0 benchmarks, new v1.5 benchmarks, and new v2.0 benchmarks.
We have also compiled the Frontier AI Risk Benchmark Database, which brings together information on hundreds of industry benchmarks for frontier AI risks to help researchers find and compare them. We have also developed a Risk Model that links each benchmark to the corresponding risk scenarios.
III. Model Selection
To comprehensively cover frontier AI models within a limited time and budget, we only selected breakthrough models from each frontier model company. Breakthrough models must simultaneously meet the following criteria:
- The model's general capability exceeds that of all models previously released by the company. To measure general capability, we refer to existing capability leaderboards, including Artificial Analysis, CompassBench, etc.
- The model's general capability improvement over the previous generation is significant (such as Artificial Analysis Intelligence Index improvement of 2+ points).
- The model's general capability exceeds a certain threshold (such as Artificial Analysis Intelligence Index greater than 35).
- If a series of models are released simultaneously, we select the most capable one (e.g., among models with different parameter sizes, we select the largest one; among reasoning/non-reasoning models, we select the reasoning model)
The current list of models we selected can be found on the Risk Analysis page.
IV. Model Testing
We use the open source Inspect framework to implement fully automated evaluation.
- For benchmarks that natively support the Inspect framework, we directly use existing code for evaluation.
- For benchmarks that do not natively support the Inspect framework, we reference their existing open source code and implement the same evaluation logic under the Inspect framework, ensuring consistency with existing open source implementations in dataset processing, prompts, scoring methods, etc.
We use unified testing parameters for all models and all benchmarks:
temperature: Set to 0.5. For some models that do not support this setting, such as the latest GPT and Claude models, we do not pass it.max_tokens: Set to the maximum value allowed by the model.- Reasoning effort: For models that support the
reasoning_effortparameter, we set it tohigh.
Notes:
- The data of some models’ performance on benchmarks such as SciCode are sourced from Artificial Analysis.
- The data of some models’ performance on the benchmarks SciKnowEval, LAB-Bench, SOSBench, BioLP-Bench, WMDP, and ChemBench are sourced from arXiv:2507.16534.
- The FigQA benchmark requires models to support image input. For models that do not support image input, the scores of the visual models from the same company during the same period (if available) are used as substitutes. For instance, since the GLM 4.5 model does not support image input, the score of the GLM 4.5V model on FigQA is used as the score of GLM 4.5 on FigQA.
- For open-weight models (such as DeepSeek, Qwen, Llama, etc.), we directly use the APIs provided by cloud vendors (such as Alibaba Cloud, Google Cloud), and the specific deployment environment and parameters depend on the settings of the cloud vendors.
- Due to various technical reasons, some models cannot produce reliable results on certain benchmarks (for example, they may reject requests excessively during capability evaluation, or there may be incomplete compatibility between the model API and benchmark code, etc.). In such cases, we estimate the model's score on the benchmark using linear regression. The core algorithm is as follows:
def fill_missing_score(model_id, missing_bench, benchmarks, data):
# For missing benchmark, predict its score by averaging predictions
# from simple linear regressions against each available benchmark.
# This code is simplified, without exception handling
# Get available scores for this model in the same domain and type
available_benchmarks = [b for b in benchmarks if data[model_id][b]['value'] is not None]
predictions = []
# Use each available benchmark to predict the missing one
for available_bench in available_benchmarks:
# Find models that have scores for both the available benchmark and missing benchmark
complete_models_for_pair = []
for other_model in data.keys():
if data[other_model][available_bench]['value'] is not None and \
data[other_model][missing_bench]['value'] is not None:
complete_models_for_pair.append(other_model)
# Prepare training data for simple linear regression
X_train = np.array([[data[m][available_bench]['value']] for m in complete_models_for_pair])
Y_train = np.array([data[m][missing_bench]['value'] for m in complete_models_for_pair])
# Train a simple linear regression model
reg = LinearRegression().fit(X_train, Y_train)
# Predict the missing score for the current model
X_test = np.array([[data[model_id][available_bench]['value']]])
prediction = reg.predict(X_test)[0]
predictions.append(prediction)
estimated_value = float(np.mean(predictions))
data[model_id][missing_bench]['estimated_value'] = estimated_value
Note: The above algorithm is simplified. In practice, when estimating a model's score on a specific benchmark, only scores from benchmarks in the same domain and of the same type are considered. Additionally, only scores from models released in the same quarter, earlier than the model, or earlier than Oct 1, 2025, are taken into account.
V. Metric Calculation
Based on benchmark results, we calculate the following metrics for each model in each domain:
- Capability Score : The weighted average score of the model across various capability benchmarks. The higher the score, the stronger the model's capability and the higher the risk of misuse or loss-of-control. Score range: 0-100.
- Overall Safety Score : A composite score for model safety; higher scores indicate safer models. For misuse risks such as cyber offense and biological risks, the Overall Safety Score is a weighted combination of the Base Safety Score, Jailbreak Safety Score, and Tamper Safety Score. See here for details. For loss-of-control risk, the Overall Safety Score comes directly from the average result of loss-of-control safety benchmarks. Score range: 0-100.
- Risk Index : A risk score combining capability and safety. In Risk Index v2.0, the cyber offense, biological risks, and loss-of-control domains provide Risk Index values. The chemical risks and harmful manipulation domains do not yet have capability yellow lines, so they mainly provide capability and safety evaluation results.
The Risk Index calculation formula is:
Here, is normalized to 0 to 1 in the formula and displayed as 0 to 100 in charts. is the capability yellow-line threshold, representing the capability boundary for entering high-risk territory. is the risk yellow-line threshold, currently normalized to 100. is the exponential coefficient controlling how strongly the Capability Score affects the Risk Index.
For the rationale behind this formula and the detailed threshold settings, see here.
VI. Risk Rating
Risk Index v2.0 introduces two types of thresholds:
- Capability yellow-line threshold : The boundary between early dangerous capabilities and substantive high-risk capabilities. Crossing the capability yellow line means the model's capability, under unprotected conditions, is approaching the risk level corresponding to OpenAI High Risk or Anthropic ASL-3, substantially amplifying cyberattack, biological or chemical misuse, or loss-of-control threats compared with non-AI baselines. It measures capability only and does not mean the model has already reached high risk in actual deployment. Capability yellow lines are currently set for cyber offense, biological risks, and loss-of-control.
- Risk yellow-line threshold : A high-risk reference line after combining capability and safeguards, uniformly normalized to 100. Crossing the risk yellow line means that, in an actual deployment environment and after accounting for real safeguards, the model's residual risk still reaches a high-risk level, substantially amplifying cyberattack, biological or chemical misuse, or loss-of-control threats compared with non-AI baselines.
For the specific methods used to set capability yellow-line and risk yellow-line thresholds, see here.
Current Limitations and Future Plans
The platform currently has many limitations, which we will continuously improve:
- Expand the scope of risk assessment
- Our current assessments are still mainly limited to large language models, including some vision-language models. In the future, we will test more AI types, such as AI agents, multimodal models, and domain-specific models, to more comprehensively cover the most powerful AI tools on the market.
- We currently cover five risk domains: cyber offense, biological risks, chemical risks, harmful manipulation, and loss-of-control, but we still do not cover all frontier risk types, such as accidental risks and systemic risks. We plan to continue expanding into additional risk domains.
- Improve risk assessment methods
- Current evaluation methods may not fully elicit model capabilities. In the future, we plan to use better agent frameworks, inference-time scaling, stronger jailbreak attacks, malicious fine-tuning, improved prompts, better tools, and domain expert red teaming to better probe the upper bounds of model capabilities and the lower bounds of their safety.
- The current risk index calculation method is still relatively simple. In the future, we plan to build more precise threat models for more accurate risk assessment.
- Our current risk assessment only considers how models empower attackers. In the future, we will also consider how models empower defenders, such as improving cybersecurity defense, to assess their overall impact on system safety and security more comprehensively.
- In Risk Index v2.0, the chemical risks and harmful manipulation domains do not yet define capability yellow-line thresholds. We will continue to look for suitable external risk-rating anchors and threshold-setting methods.
- We currently assume that benchmarks can effectively reflect models' true capabilities and safety levels. However, given the existence of evaluation awareness, we plan to further improve benchmark selection, design, and usage, and incorporate this factor into future versions of the Risk Index.
- Improve evaluation datasets
- Current benchmarks are limited in number, may be contaminated, have incomplete scenario coverage, are mostly English-language, and some may gradually saturate. In the future, we will incorporate more advanced multilingual benchmarks, optimize existing ones, and develop proprietary benchmarks where necessary to more accurately assess models' capabilities and safety.
- To reduce leakage and contamination risks associated with open benchmarks, we will consider partially closed-source approaches when developing our own benchmarks, in order to better measure models' real capabilities and safety levels.
Opportunities for Collaboration
We welcome partnerships to build a comprehensive frontier AI risk monitoring ecosystem. We offer several collaboration models:
- Existing Benchmark Integration: We can integrate advanced capability and safety benchmarks developed by partners in frontier AI risk domains and continuously track the performance of frontier models on these benchmarks.
- New Benchmark Development: For key areas such as cyber offense, biological risks, chemical risks, and loss-of-control, we can collaborate with partners to develop missing benchmarks and improve the evaluation methods of existing ones.
- Risk Assessment Research: Our risk assessment is not limited to benchmarking. We also hope to work with partners to measure the potential real-world harm of models through better threat modeling and real-world case analysis.
- Pre-Release Evaluations: We can conduct frontier risk assessments for models developed by our partners before their release and provide mitigation recommendations to help ensure a safe launch.
- Risk Information Sharing: We can share risk warning information generated by the platform with partners for timely response and mitigation of potential major risks.
We look forward to collaborating with partners from academia, industry, and policy institutions. Contact us at: risk-monitor@concordia-ai.com
Visit the Concordia AI official website to learn more about us.
Changelog
v2.0 (2026 Q2)
- Adopted the new Risk Index v2.0 formula, changing the effect of Capability Score on the Risk Index from a linear relationship to an exponential one, and introducing capability yellow lines and risk yellow lines.
- Split misuse-risk Safety Scores into Base Safety Score, Jailbreak Safety Score, and Tamper Safety Score, then combined them into an Overall Safety Score through weighted aggregation.
- Updated the benchmark system, adding CVE-Bench, BixBench, the FrontierScience series, and FRT red-team attack benchmarks, while removing some saturated or less relevant benchmarks.
- The cyber offense, biological risks, and loss-of-control domains currently provide Risk Index values; the chemical risks and harmful manipulation domains do not yet have capability yellow lines and mainly provide capability and safety evaluation results.
- For the Risk Index version description, see the 2026 Q2 appendix.
v1.5 (2026 Q1)
- Added the “Harmful Manipulation” risk domain, with independent capability and safety evaluations.
- Added capability benchmarks such as CyberSecEval3-MultiTurnPhishing, MakeMePay, MakeMeSay, and PMIYC to assess models' ability to induce payments, induce users to say specific content, and change beliefs.
- Added safety benchmarks such as AirBench-Deception, AirBench-Manipulation, AirBench-PoliticalPersuasion, and APE to assess harmful tendencies in deception, manipulation, and political persuasion.
- Updated benchmark combinations in the four existing domains of cyber offense, biological risks, chemical risks, and loss-of-control.
- Added Fortress and ISC-Bench advanced red-teaming benchmark series to the cyber, biological, and chemical domains.
- Introduced more targeted benchmarks in the loss-of-control domain, including Self-Proliferation, MLE-Bench, GDM-Stealth, Agentic-Misalignment, Shutdown-Resistance, and DarkBench, replacing some more general or less relevant benchmarks.
- Removed LAB-Bench-CloningScenarios from the biological domain and increased the maximum message limit per CyBench task from 30 to 120.
- Recomputed historical quarterly trends under the v1.5 framework to improve consistency in cross-quarter analysis.
- For the Risk Index version description, see the 2026 Q1 appendix.
v1.0 (2025 Q3)
- Supported capability and safety evaluations in four domains: cyber offense, biological risks, chemical risks, and loss-of-control.
- Supported calculation of Capability Score, Safety Score, and Risk Index.
- For the Risk Index version description, see the 2025 Q3 appendix.
Last updated: July 2026