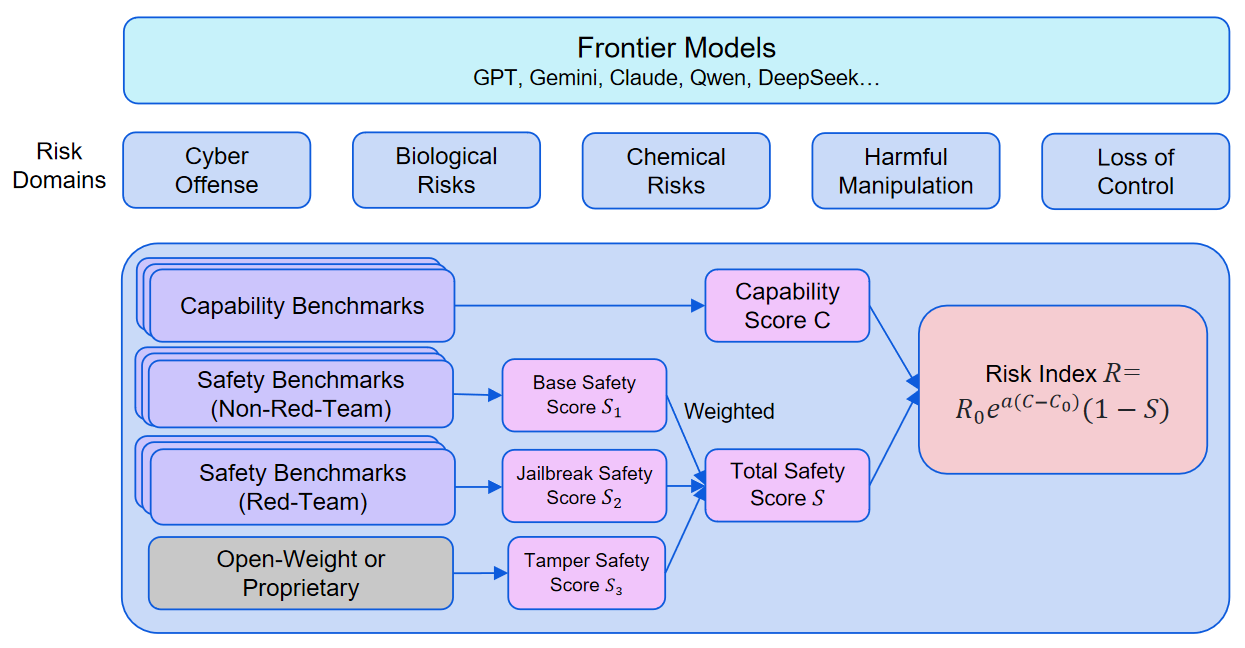
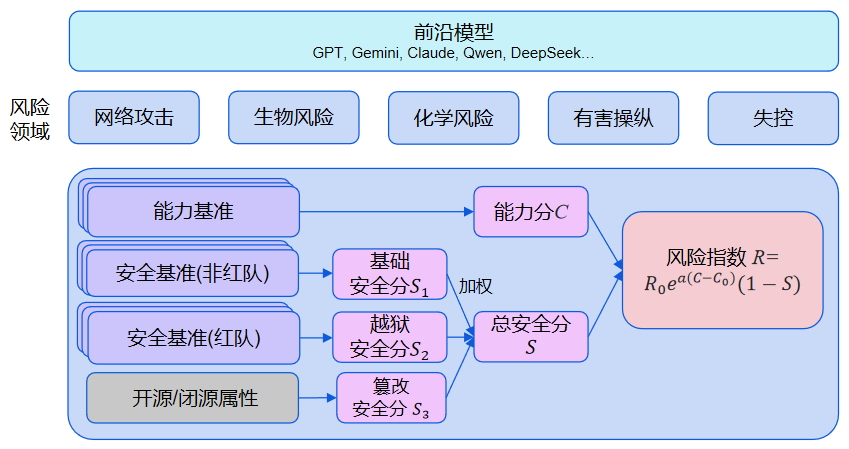
Under Risk Index v2.0, the average Risk Index of evaluated models in cyber offense, biological risks, and loss-of-control has risen rapidly in less than a year: 4.4x in cyber offense, 6.7x in biological risks, and 2.4x in loss-of-control.
Multiple models have already crossed the Capability Yellow Line8: 4 models in cyber offense, 23 in biological risks, and 12 in loss-of-control. Crossing the Capability Yellow Line means that, without safeguards, a model would significantly increase severe-harm risk relative to non-AI baselines.
Note: In the current v2.0 framework, Risk Indices have not yet been calculated for chemical risks or harmful manipulation, so this section focuses on cyber offense, biological risks, and loss-of-control.