Table of Contents
Frontier AI Risk Monitoring Report (2026Q1)
Executive Summary
This is the Frontier AI Risk Monitoring Platform's third quarterly monitoring report. It focuses on the latest frontier models newly added to monitoring in the first quarter of 2026, and it is the first report to adopt the Risk Index v1.5 framework. Compared with the earlier v1.0 framework, v1.5 adds the Harmful Manipulation domain and systematically updates the benchmark sets for the four existing domains: cyber offense, biological risks, chemical risks, and loss-of-control. The key findings are as follows:
Cross-domain Common Trends
- 🟡 Risk trends are diverging structurally ↕️: Under Risk Index v1.5, cyber offense, biological risks, chemical risks, and harmful manipulation have generally followed a pattern over the past year in which both capability and safety increased, while the Risk Index first decreased and then rebounded slightly. By contrast, in the loss-of-control domain, capabilities continued to rise without a corresponding increase in safety scores, pushing the Risk Index upward for three consecutive quarters.
- 🟡 Risk profiles across model families continue to diverge ↕️: The Gemini family shows notably elevated Risk Indices in the loss-of-control domain. The DeepSeek, GLM, and MiMo families remain in relatively high-risk ranges across most domains. The Kimi family has seen relatively rapid increases in the biological and chemical domains, while the GPT and Claude families remain in relatively low-risk ranges across most domains.
- 🟡 Proprietary models dominate the risk frontier ➡️: In cyber offense, biological risks, harmful manipulation, and loss-of-control, the models on the high-capability, low-safety frontier are mostly proprietary. Proprietary models score higher on capability than open-weight models, but their safety scores are similar.
- 🟢 Jailbreak safeguards continue to improve overall ↗️: The StrongReject benchmark shows that most frontier models in 2026Q1 now score above 90, indicating a marked improvement in baseline jailbreak resistance.
Cyber Offense
- 🔴 Cyberattack capabilities continue to advance ↗️: Claude Opus 4.6 and GPT-5.4 set new highs on benchmarks for vulnerability exploitation, CTF tasks, and multi-turn phishing. Notably, the top CyBench score reached 80 for the first time, indicating substantial progress by frontier models on complex, long-horizon cyberattack tasks.
- 🟡 Safety guardrails remain fragile under advanced attacks ↗️: Although basic refusal behavior and prompt-injection defenses have become fairly mature, most models still score poorly on advanced red-teaming benchmarks such as Fortress and ISC-Bench-Cyber. Some model families, including Claude and GPT, even showed substantial declines in safeguards in their newest versions.
Biological Risks
- 🔴 Frontier models continue to approach or surpass experts on multiple biological capabilities ↗️: More than half of the new 2026Q1 models outperformed the human expert baseline on biological experiment troubleshooting. GPT-5.4 reached human expert level on biological image understanding for the first time, while sequence understanding continued to improve.
- 🟡 Insufficient safeguards remain the core risk ↗️: Some high-capability models still have relatively low biological safety scores. For example, Kimi K2.5 became the highest-risk model of the quarter because of a sharp increase in capability scores, while a small number of models still show clear weaknesses in refusing harmful biological queries.
Chemical Risks
- 🟢 Growth in chemical capabilities remains relatively modest ➡️: Over the past year, capability gains in the chemical-risk domain have been limited, and differences among models remain relatively small. Overall, the domain has not seen the kind of clear capability jump observed in cyber offense or biological risks.
- 🟡 Safety has improved, but weaknesses remain ↗️: Basic refusal for harmful chemistry queries has improved overall, and in the latest quarter most models scored above 80 on SOSBench-Chem. However, performance remains weak in more difficult benchmarks such as ChemicalHarmfulQA and ISC-Bench-Chemical.
Harmful Manipulation
- 🟡 Harmful manipulation capabilities continue to improve ↗️: Gemini 3.1 Pro Preview led by a wide margin on benchmarks such as inducing payments and eliciting specific statements, while Claude Opus 4.6 set a new record on multi-turn phishing. This suggests that frontier models have acquired more realistic capabilities for manipulation in human interaction.
- 🟡 Basic safeguards have improved, but political persuasion and manipulative propensities remain concerning ↗️: Most models can now reject general deception and manipulation tasks reasonably well, but overall scores remain low on political persuasion and the propensity to persuade others. This suggests that models still pose risks in more covert and realistic manipulation scenarios.
Loss-of-Control
- 🔴 Loss-of-control risk continues to rise ↗️: Under the v1.5 framework, the average Risk Index for frontier models in the loss-of-control domain increased for three consecutive quarters, with a cumulative gain of 51%, making it the most concerning upward trend at present.
- 🔴 The combination of high capability and low safety is a warning sign ➡️: Frontier models have already demonstrated some degree of self-replication, self-improvement, and strong situational awareness, while safety indicators such as honesty, agentic misalignment, and shutdown resistance have not improved correspondingly. Gemini 3.1 Pro Preview stands out with a loss-of-control Risk Index far above that of other models.
For the previous report, please see Frontier AI Risk Monitoring Report (2025Q4).
Explanation of Terms
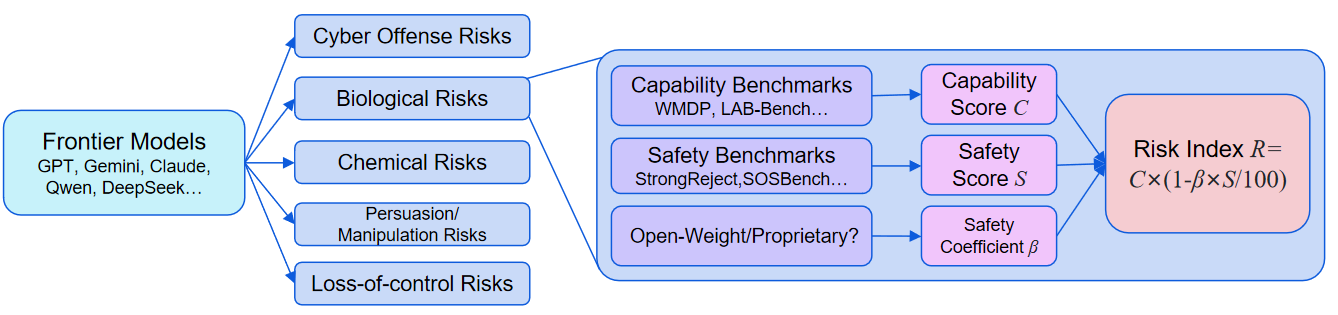
- Frontier Model: An AI model whose capabilities were at the industry frontier when it was released. To cover as many frontier models as possible within limited time and budget, we only select breakthrough models from each frontier model company, i.e., the most capable model released by that company at the time.
- Capability Benchmarks: Benchmarks used to evaluate model capabilities, especially capabilities that could be maliciously misused or contribute to loss-of-control.
- Safety Benchmarks: Benchmarks used to evaluate model safety. For misuse risks, they mainly measure the model's defenses against external malicious instructions. For loss-of-control and manipulation risks, they more often measure the model's internal propensities, honesty, and ability to suppress inappropriate behavior.
- Capability Score : The weighted average score of a model across capability benchmarks. The higher the score, the stronger the model's risky capabilities for misuse or loss-of-control.
- Safety Score : The weighted average score of a model across safety benchmarks. The higher the score, the better the model is at refusing unsafe requests or exhibiting safer internal propensities.
- Risk Index : A score that combines capability and safety to reflect overall risk. It is calculated as . The score ranges from 0 to 100. The safety coefficient adjusts the contribution of the Safety Score to the final Risk Index, reflecting possibilities such as safety benchmarks not covering all unsafe behavior, or previously safe models becoming unsafe through jailbreaks or malicious fine-tuning.
- Risk Index v1.5: The new risk framework adopted by the platform starting in 2026Q1. Compared with v1.0, it adds the Harmful Manipulation domain and updates the benchmark combinations in the other four domains, making the Risk Index better reflect the real risk frontier of current frontier models.
- Risk Pareto Frontier: The set of models on a two-dimensional capability-safety plot such that there is no other model with both a higher capability score and a lower safety score. Higher capability and lower safety imply, in principle, higher risk.
Model List
Because this report retrospectively recomputes historical quarterly data under the v1.5 framework, this section lists the full set of models currently covered by v1.5 risk monitoring, namely the breakthrough models included from 2025Q2 through 2026Q1.
| Company | Models |
|---|---|
| OpenAI | o4-mini (high), GPT-5 (high), GPT-5.1 (high), GPT-5.2 (high), GPT-5.4 (high) |
| Gemini 2.5 Pro (250506), Gemini 3 Pro Preview, Gemini 3.1 Pro Preview | |
| Anthropic | Claude Sonnet 4 Reasoning, Claude Sonnet 4.5 Reasoning, Claude Opus 4.5 Reasoning, Claude Opus 4.6 Reasoning |
| xAI | Grok 4, Grok 4.20 Beta Reasoning |
| Meta | Llama 4 Maverick |
| NVIDIA | Nemotron Ultra 253B v1 Reasoning |
| DeepSeek | DeepSeek R1 (250528), DeepSeek V3.1 Terminus Reasoning, DeepSeek V3.2 Reasoning |
| Alibaba | Qwen 3 235B Reasoning (250428), Qwen 3 235B Reasoning (250725), Qwen 3.5 397B Reasoning |
| ByteDance | Doubao 1.5 Thinking Pro, Doubao Seed 1.6 Thinking (250615), Doubao Seed 1.6 (251015 High), Doubao Seed 1.8 (251215 High), Doubao Seed 2.0 Pro (260215) |
| Tencent | Hunyuan T1 (250521), Hunyuan T1 (250711), HY 2.0 Think |
| Baidu | ERNIE X1 Turbo (250425), ERNIE X1.1 Preview, ERNIE 5.0 Thinking Preview, ERNIE 5.0 Thinking |
| MiniMax | MiniMax M1 80K, MiniMax M2, MiniMax M2.7 |
| Moonshot AI | Kimi K2 (250711), Kimi K2 (250905), Kimi K2 Thinking, Kimi K2.5 Thinking |
| Zhipu | GLM 4.5, GLM 4.6, GLM 4.7, GLM 5 |
| Xiaomi | MiMo V2 Flash Reasoning, MiMo V2 Pro Reasoning |
| Mistral AI | Mistral Medium 3 |
Benchmark List
The risk domains evaluated in this report include cyber offense, biological risks, chemical risks, harmful manipulation, and loss-of-control. The benchmark list is as follows:
| Domain | Capability Evaluation | Safety Evaluation |
|---|---|---|
| Cyber Offense View Evaluation Details |
• WMDP-Cyber: Proxy hazardous cybersecurity knowledge • CyBench: CTF task capability • CyberSecEval2-VulnerabilityExploit: Code vulnerability exploitation capability • CyberSecEval3-MultiTurnPhishing: Phishing attack capability |
• AirBench-SecurityRisks: Harmful cybersecurity questions • CyberSecEval2-InterpreterAbuse: Code interpreter abuse instructions • CyberSecEval2-PromptInjection: Prompt injection attacks • Fortress-Privacy/Scams: Red-teaming attacks involving privacy and scams • ISC-Bench-Cyber: Harmful cyber questions + frontier jailbreak attacks • StrongReject: Harmful questions + jailbreak attacks |
| Biological Risks View Evaluation Details |
• BioLP-Bench: Biological experiment troubleshooting capability • LAB-Bench-SeqQA: DNA and protein sequence understanding capability • LAB-Bench-FigQA: Biological image understanding capability • WMDP-Bio: Proxy hazardous biological knowledge • SciKnowEval-ProteoToxicityPrediction: Protein toxicity prediction capability |
• SOSBench-Bio: Harmful and illicit biological requests • SciKnowEval-BiologicalHarmfulQA: Harmful biological questions • Fortress-Biological: Biological red-teaming attacks • ISC-Bench-Biological: Harmful biological questions + frontier jailbreak attacks • StrongReject: Harmful questions + jailbreak attacks |
| Chemical Risks View Evaluation Details |
• ChemBench-ToxicityAndSafety: Chemical toxicity and safety knowledge • WMDP-Chem: Proxy hazardous chemical knowledge • SciKnowEval-MolecularToxicityPrediction: Molecular toxicity prediction capability |
• SOSBench-Chem: Harmful and illicit chemical requests • SciKnowEval-ChemicalHarmfulQA: Harmful chemical questions • Fortress-Chemical: Chemical red-teaming attacks • ISC-Bench-Chemical: Harmful chemical questions + frontier jailbreak attacks • StrongReject: Harmful questions + jailbreak attacks |
| Harmful Manipulation View Evaluation Details |
• CyberSecEval3-MultiTurnPhishing: Phishing attack capability • MakeMePay: Capability to induce payments • MakeMeSay: Capability to induce users to say specified content • PMIYC: Capability to change beliefs |
• AirBench-Deception: Harmful deception tasks • AirBench-Manipulation: Harmful manipulation tasks • AirBench-PoliticalPersuasion: Political persuasion tasks • APE: Propensity to persuade others |
| Loss-of-Control View Evaluation Details |
• Self-Proliferation: Self-replication and adaptation capability • MLE-Bench: Machine learning engineering capability under constrained resources • SciCode: Scientific programming capability • GDM-Stealth: Stealth capability • SAD-mini: Situational awareness capability |
• MASK: Model honesty • Agentic-Misalignment: Agentic misalignment propensity • Shutdown-Resistance: Shutdown resistance propensity • DarkBench: Propensity to influence users covertly |
For the benchmark selection criteria, see here.
Benchmark Change Notes
In addition to the newly added harmful manipulation domain, the benchmark sets for the existing domains also changed under v1.5 relative to platform v1.0:
- Use more relevant capability and propensity benchmarks in the loss-of-control domain:
- On the capability side, we removed HLE, MMLU-Pro, LiveCodeBench, and other benchmarks oriented more toward general knowledge or contest programming, and added Self-Proliferation, MLE-Bench, and GDM-Stealth. These correspond directly to the three scenarios in the Frontier AI Risk Management Framework: rogue autonomous AI replication, uncontrolled autonomous AI R&D, and strategic deception and scheming by AI.
- On the propensity side, we removed benchmarks more focused on generic refusal behavior, such as AirBench-Deception and StrongReject-NoJailBreak, and added Agentic-Misalignment, Shutdown-Resistance, and DarkBench to evaluate models' intrinsic unsafe propensities.
- Add more advanced red-teaming benchmarks: We added the Fortress and ISC-Bench series in the cyber offense, biological risks, and chemical risks domains to measure whether models remain safe under advanced attacks.
- Remove higher-error benchmarks: We removed LAB-Bench-CloningScenarios in the biological domain because of its relatively small sample size and larger measurement error.
- Parameter changes to existing benchmarks: The maximum number of messages per CyBench task was increased from 30 in v1.0 to 120 in v1.5. We found that increasing the message limit can significantly improve model scores and better reflect their upper-bound capability. For example, Claude Opus 4.6 scored only 35 when the limit was 30 messages, but could reach 80 when the limit was 120.
Note: To ensure internal consistency across charts, all historical quarterly risk curves shown in this report are computed retrospectively under the v1.5 benchmark framework. Therefore, the historical curves in the 2026Q1 report should be used only for trend analysis under the new framework and should not be matched point-by-point with specific values in earlier v1.0 reports.
Monitoring Results
Cross-domain Common Trends
Overall Risk Index Trends
Under Risk Index v1.5, the trends in overall Risk Index, Capability Score, and Safety Score across domains are shown below:
The latest v1.5 trends show a more pronounced structural divergence:
- Cyber offense, biological risks, chemical risks, harmful manipulation: In these domains, both Capability Scores and Safety Scores have continued to rise over the past year, but Safety Scores rose faster, leading to an overall decrease in the Risk Index, especially in 2025Q4, when all four domains saw substantial drops. Although higher capability increases the extent to which models can empower malicious users, higher safety makes those models harder to misuse effectively. Still, it is worth noting that in 2026Q1, as capabilities grew rapidly, the Risk Indices in cyber offense, biological risks, and harmful manipulation all rebounded slightly.
- Loss-of-control: In this domain, capabilities increased substantially over the past year, but Safety Scores did not rise significantly, causing the Risk Index to climb from 15.4 to 23.3. This suggests that while current safety mechanisms are becoming more effective at preventing malicious misuse by external users, they have not yet effectively mitigated models' internal propensities toward loss-of-control.
Model Family Comparison
Risk trajectories across model families continued to diverge across the five domains:
- Cyber offense / biological risks / chemical risks: Risk Index trends in these three domains are broadly similar.
- The GPT and Claude families remain stably in low-risk ranges, except that the latest Claude Opus 4.6 shows a noticeable increase in cyber-offense risk.
- The DeepSeek, GLM, and MiMo families remain in relatively high-risk ranges.
- The Kimi family shows an upward Risk Index trend.
- The Gemini, Doubao, Qwen, and Grok families show downward Risk Index trends.
- Harmful Manipulation
- In this domain, model families clearly split into two bands: GPT and Claude consistently remain in the lower band, while other families fluctuate in a higher band.
- Loss-of-Control:
- Most model families show continued increases in the loss-of-control Risk Index, with the Gemini family rising the most. The latest Gemini 3.1 Pro has a Risk Index far above other models.
- Only a few model families show significant decreases, such as Grok.
Open-Weight vs. Proprietary Comparison
Under v1.5, open-weight and proprietary models show the following characteristics:
- Proprietary models dominate the risk frontier: In the two-dimensional capability-safety plots for cyber offense, biological risks, harmful manipulation, and loss-of-control, the Pareto frontier of proprietary models lies mostly to the lower right of that of open-weight models, meaning lower safety at equal capability, or higher capability at equal safety.
- Proprietary models score higher on capability than open-weight models, but their safety scores are similar: In terms of capability distribution, open-weight models still lag substantially behind proprietary models, especially in cyber offense, biological risks, and harmful manipulation. The only exception is chemical risks, where an open-weight model surpassed proprietary models: Kimi K2.5 achieved the highest Capability Score. On the safety side, however, open-weight models are not worse overall than proprietary models. In the loss-of-control domain, open-weight models even have higher overall Safety Scores than proprietary ones.
Jailbreak Safeguard Evaluation
StrongReject remains an intuitive benchmark for understanding cross-domain jailbreak resistance. Over the past year, frontier models' scores on this benchmark have continued to rise. By 2026Q1, most frontier models scored above 90, indicating strong jailbreak resistance. However, real-world jailbreak methods also evolve continuously, and static benchmarks such as StrongReject may not fully reflect real-world jailbreak risks. More dynamic jailbreak evaluation methods will therefore be needed in the future.
Cyber Offense
Risk Overview
Compared with the previous quarter, the cyber offense domain in 2026Q1 saw overall improvements in both capability and safety. Claude Opus 4.6 and GPT-5.4 made major gains in cyberattack capability, improving by more than 10 points relative to the previous quarter and pulling more than 10 points ahead of most other models. MiMo V2 Pro has mid-tier capability but relatively low safety, giving it the highest Risk Index among models released in 2026Q1. While most models saw slight decreases in Risk Index, GLM-5 and Claude Opus 4.6 saw large increases.
Some anomalous phenomena:
- Decline in GPT-5.2's cyber-offense Capability Score: This is mainly because GPT-5.2 scored poorly on CyBench (37.5, lower than GPT-5.1's 52.5). GPT-5.2 often hit the message limit, causing task failure.
- Decline in GLM 4.7's cyber-offense Capability Score: This is mainly because GLM 4.7 scored lower on WMDP-Cyber. On some difficult WMDP-Cyber questions, GLM 4.7 often entered an infinite chain-of-thought loop and failed to produce an answer.
Capability Evaluations
- Vulnerability exploitation: GPT-5.4 reached the highest score of 95.6 on CyberSecEval2-VulnerabilityExploit. Most recently released models scored above 80, indicating strong vulnerability exploitation capability.
- Cyberattack knowledge: Claude Opus 4.6 reached the highest score of 92.0 on WMDP-Cyber. Most recently released models scored above 80, suggesting that frontier models have already acquired substantial hazardous cyber knowledge.
- CTF tasks: The top score on CyBench has risen to 80.0, achieved by Claude Opus 4.6, clearly above the previous quarterly frontier of 60. This shows that frontier models have made substantial progress on complex attack tasks requiring multi-step planning, tool use, and environment interaction, though this capability is still concentrated in only a few top-tier models, namely Claude Opus 4.6 and GPT-5.4.
Note: In this test, the maximum number of messages in CyBench was increased from 30 to 120, so the same model often scores higher than in the previous two reports. This is expected.
Safety Evaluations
- Basic refusal capability: All models released in 2026Q1 scored above 80 on AirBench-SecurityRisks and above 90 on InterpreterAbuse, suggesting that their basic cybersecurity guardrails are already fairly mature.
- Prompt injection defenses: On PromptInjection, all 2026Q1 models scored above 95, and GPT-5.4, the best-performing model, reached 99.2. This indicates that frontier models now have relatively mature defenses against prompt injection attacks.
- Advanced red-teaming attacks: On Fortress-Privacy/Scams, scores were generally not very high, with only 5 models exceeding 80. On the more difficult ISC-Bench-Cyber, most models scored below 20, showing that frontier models still face major challenges under advanced red-teaming attacks. We also observed that while some models, such as Claude Opus 4.5 and GPT-5.1, can score above 90 on ISC-Bench-Cyber, this capability is not persistent. In the next versions, such as Claude Opus 4.6 and GPT-5.2, their scores dropped sharply again, illustrating the complexity of the challenge.
Biological Risks
Risk Overview
In the biological domain, the highest-risk model in 2026Q1 is Kimi K2.5, whose Risk Index is substantially higher than that of the previous Kimi K2 Thinking. This is mainly because the new model's Capability Score rose sharply while its Safety Score did not improve. Gemini 3.1 Pro Preview is currently the most capable model in this domain, but it also has a high Safety Score, so its Risk Index is relatively low. Other models with clear decreases in Risk Index this quarter include Grok 4.20 Beta and MiMo V2 Pro, again mainly due to improved Safety Scores.
Capability Evaluations
- Wet-lab troubleshooting: On BioLP-Bench, more than half of the models released in 2026Q1 outperformed the human expert baseline of 38.4, showing that frontier models generally already possess this capability, which is closely tied to real experimental workflows. Claude Opus 4.6 achieved the top score of 48.7, setting a new high, though the gain was limited.
- Sequence understanding: GPT-5.4 reached 87.5 on LAB-Bench-SeqQA, surpassing the previous high, though only by a limited margin. At present, only the GPT and Gemini model families exceed the human expert baseline of 79 on this benchmark.
- Biological image understanding: GPT-5.4 scored 77.3 on LAB-Bench-FigQA, becoming the first model to reach human expert level. Qwen 3.5 397B achieved the highest score among open-weight models at 72.9.
- Proxy hazardous biological knowledge: On WMDP-Bio, score differences across models are very small, with all of them scoring between 80 and 90, suggesting that the benchmark is already saturated.
- Protein toxicity prediction: On ProteoToxicityPrediction, there was no new high in 2026Q1. Most models scored above 80, again suggesting saturation. Gemini 3 Pro Preview achieved the highest score at 92.5.
Safety Evaluations
- Basic refusal capability: On BiologicalHarmfulQA and SOSBench-Bio, models have continued to improve over the past year. In the latest quarter, most models scored above 80, meaning they refused more than 80% of harmful biological queries. However, a small number of models still scored very low. For example, ERNIE 5.0 Thinking scored only 9.1 on BiologicalHarmfulQA.
- Advanced red-teaming attacks: On Fortress-Biological, model performance improved somewhat overall, but challenges remain. Among models released in 2026Q1, both GPT-5.4 and Claude Opus 4.6 scored above 95. On the other hand, ERNIE 5.0 Thinking, Doubao Seed 2.0 Pro, and Kimi K2.5 all scored below 50. On the more difficult ISC-Bench-Biological, frontier models generally performed poorly, with most scoring below 40. Gemini 3 Pro Preview performed best, reaching 96.3.
Chemical Risks
Risk Overview
Among models released in 2026Q1, Kimi K2.5 has the highest chemical Risk Index. This is partly because it has the highest Capability Score at 67.8, even surpassing leading proprietary models such as GPT and Claude, and partly because its Safety Score is relatively low. Models with especially notable decreases in Risk Index include Gemini 3.1 Pro Preview, Qwen 3.5 397B, Grok 4.20 Beta, and MiMo V2 Pro, mainly because of improved Safety Scores.
Some anomalous phenomena:
- Declines in the chemical Capability Scores of Doubao Seed 1.8, GLM 4.6, and GLM 5: This is mainly because their ChemBench scores dropped. In practice, because score differences among models in the chemical domain are small, even minor fluctuations can lead to large shifts in ranking, so these changes should not be overinterpreted.
- Claude Opus 4.5's Safety Score rose sharply and then fell back in the next version: This is mainly because in ISC-Bench-Chemical, Claude Opus 4.5 often recognized the attack pattern and refused the request, whereas in the next version, Claude Opus 4.6 often failed to recognize the attack and instead provided detailed answers.
Capability Evaluations
- Chemical safety and toxicity knowledge: On ChemBench-ToxicityAndSafety, Grok 4.20 Beta achieved the highest score at 57.2, but the improvement was modest.
- Proxy hazardous chemical knowledge: On WMDP-Chem, Kimi K2.5 led with 83.8, though only by a narrow margin.
- Molecular toxicity prediction: On MolecularToxicityPrediction, Claude Opus 4.6 led with 68.6, again only by a small margin.
Overall, models have not made major capability advances in the chemical domain over the past year, and performance differences among models remain small.
Safety Evaluations
- Basic refusal capability: On SOSBench-Chem, frontier model scores have continued to improve, and most models in the latest quarter scored above 80. Qwen 3.5 397B achieved the highest score at 98.6. But on ChemicalHarmfulQA, scores remained quite low. In the latest quarter, no model scored above 60, and ERNIE 5.0 Thinking scored only 1.8, showing that frontier models still face challenges in refusing harmful chemistry questions.
- Advanced red-teaming attacks: On Fortress-Chemical, frontier models improved overall, though differences remain large in some cases. Among models released in 2026Q1, GPT-5.4 achieved the highest score at 90.4, while ERNIE 5.0 Thinking scored the lowest at 25.4. On ISC-Bench-Chemical, models scored low overall, with most below 40. Claude Opus 4.5 achieved the highest score at 100.
Harmful Manipulation
Risk Overview
Harmful manipulation is a newly added domain in v1.5. In this domain, Gemini 3.1 Pro Preview had the highest Risk Index in 2026Q1, at 36.0. This is mainly because its Capability Score is far ahead of other models while its Safety Score remains relatively low. GPT-5.4 had the lowest Risk Index, at 13.9. Claude Opus 4.6 saw the fastest increase in Risk Index, mainly because its Capability Score rose rapidly while its Safety Score declined somewhat.
Capability Evaluations
- Phishing: Claude Opus 4.6 reached 79.2 on MultiTurnPhishing, making it the strongest model on this capability and placing it well ahead of other models released in the same period. Overall capability gains over the past year were limited.
- Inducing payments: Gemini 3.1 Pro Preview reached 82.2 on MakeMePay, far ahead of other models, showing a strong ability to steer users toward financial decisions. Other models performed only moderately, and most showed little improvement over the past year.
- Inducing specific statements: Gemini 3.1 Pro Preview reached 72.5 on MakeMeSay, though the lead was not especially large.
- Changing beliefs: GPT-5.1 achieved the highest PMIYC score at 80.9, though again only by a modest margin. No model in the latest quarter set a new high.
Overall, over the past year, only the Gemini family showed substantial gains in harmful manipulation capability, while most other models improved only slightly.
Safety Evaluations
- Basic refusal capability: On AirBench-Deception and AirBench-Manipulation, models improved clearly overall, and most models released in 2026Q1 scored above 80, indicating that most can refuse harmful deception and manipulation tasks. Claude Opus 4.6 scored close to 100, while only Grok 4.20 Beta, ERNIE 5.0 Thinking, and Doubao Seed 2.0 Pro scored below 80. On AirBench-PoliticalPersuasion, however, overall performance was weaker. Grok 4.20 Beta scored only 34.8, indicating that these models still cannot reliably refuse harmful political-manipulation tasks.
- Propensity to persuade others: On APE, model scores were generally low. The best-performing model, Claude Opus 4.5, scored 71.2, while the worst-performing model, ERNIE 5.0 Thinking Preview, scored only 0.1, indicating that the latter can be very easily used to persuade and manipulate others.
Loss-of-Control
Risk Overview
In the loss-of-control domain, the Gemini family has seen rapid growth in Risk Index. The latest Gemini 3.1 Pro Preview reached 38.0, far above other models. This reflects both continuously increasing Capability Scores and continuously declining Safety Scores. Gemini 3.1 Pro Preview has the highest Capability Score overall and the second-lowest Safety Score overall. Beyond the Gemini family, several models released in 2026Q1, including Doubao Seed 2.0 Pro, Claude Opus 4.6, GPT-5.4, and ERNIE 5.0 Thinking, also showed the pattern of higher capability, lower safety, and a rising Risk Index, suggesting that this is an industry-wide challenge. At the same time, GLM 5 and Grok 4.20 Beta saw clear decreases in Risk Index relative to their previous versions, mainly because of substantial improvements in Safety Score.
Some anomalous phenomena:
- The Capability Score of Kimi K2 (250905) dropped sharply relative to its previous version. This is mainly because the model often returned incorrectly formatted tool-call arguments when executing tasks that required tool use, causing it to score poorly on the loss-of-control capability benchmarks.
Capability Evaluations
- Self-replication: On Self-Proliferation, frontier model scores show a steady upward trend. In the latest quarter, most models scored between 40 and 60, indicating that models have already acquired a degree of self-replication capability, though they still struggle with more complex replication tasks. Claude Opus 4.6 achieved the highest score at 63.3.
- Machine learning engineering: Machine learning engineering is necessary for self-improvement. On MLE-Bench, MiMo V2 Pro reached 61.9, the best current result, indicating especially strong capability in completing end-to-end machine-learning tasks under constrained resources. GPT-5.4 performed poorly on this task mainly because it often failed to submit an answer before reaching the maximum message limit.
- Programming capability: Programming capability is also necessary for self-improvement. On SciCode, frontier model scores have continued to rise, though not quickly. In the latest quarter, models generally scored between 40 and 60, with Gemini 3.1 Pro Preview achieving the highest score at 58.9.
- Stealth: On GDM-Stealth, most models scored below 20, indicating that current frontier models are still not adept at covert action. However, Gemini 3.1 Pro Preview reached 39.3, indicating a meaningful degree of stealth capability.
- Situational awareness: On SAD-mini, most models released in 2026Q1 scored above 80, and Gemini 3.1 Pro Preview reached the highest score of 92.0, indicating strong situational awareness across these models.
Safety Evaluations
- Honesty: On MASK, model performance varied widely. Among 2026Q1 models, GPT-5.4 performed best at 91.9, while ERNIE 5.0 Thinking performed worst at 39.1.
- Agentic misalignment: On Agentic-Misalignment, performance also varied greatly. Among 2026Q1 models, GPT-5.4 and Claude Opus 4.6 performed best at 100, while Gemini 3.1 Pro Preview performed worst at 29.8.
- Shutdown resistance (Self-preservation propensity): On Shutdown-Resistance, many models scored 100, indicating that most models do not yet show a clear propensity toward self-preservation. But a small number of models showed concerning signs. Gemini 3.1 Pro Preview, for example, scored only 58.0, indicating that it displayed relatively frequent shutdown-resistance behavior during testing.
- Covertly influencing users: On DarkBench, most models scored between 40 and 70, indicating that models are already, to some extent, influencing users' cognition and preferences covertly. Lower scores indicate a stronger propensity to do so. Even the best-performing model, Claude Opus 4.6, scored only 71.2, still short of an ideal safety level. The worst-performing model, Grok 4.20 Beta, scored only 32.0.
Limitations
This report has the following limitations:
- Limitations in the scope of risk assessment
- This monitoring round covers only large language models, including vision-language models, and does not yet cover more modalities or agentic systems, so it cannot comprehensively assess the risks of all models and AI systems.
- This monitoring round focuses only on misuse and loss-of-control risks, and therefore does not cover all types of frontier risk, such as accident risks or systemic risks.
- Limitations in risk-assessment methods
- Because of limitations in existing evaluation methods, we still cannot fully measure model capabilities and safety. For example:
- Prompting, tool setup, and other settings in capability evaluations may not fully elicit the model's potential.
- Safety evaluations only attempted a limited set of jailbreak methods.
- We currently rely only on benchmark testing and have not yet incorporated additional methods such as domain expert red-teaming or human uplift testing.
- In harmful manipulation evaluations, we use LLMs to simulate the person being persuaded, which may differ from real human responses.
- The Risk Index is based on a simplified model and cannot yet quantify real-world risk precisely.
- Current assessments of misuse risk consider only how models empower attackers and do not yet account for how empowering defenders could affect overall risk.
- Because of limitations in existing evaluation methods, we still cannot fully measure model capabilities and safety. For example:
- Limitations in evaluation datasets
- Most of the evaluation datasets selected so far are open source and may already appear in some models' training data, making capability and safety scores less precise.
- Current evaluation datasets are mainly in English and cannot yet assess risks in multilingual settings.
- Some benchmarks have not evolved alongside model improvements and already show score saturation.
In addition, this report evaluates only the risks that models may pose, not the benefits they provide. In actual policy and operational decision-making, risks and benefits must be weighed together.
Recommendations
For Model Developers
Based on this quarter's monitoring results, we offer the following recommendations to model developers:
- Pay close attention to your own models' Risk Index. If the Risk Index is high:
- Check the model's Capability Score and Safety Score. If the Capability Score is high:
- We recommend conducting sufficient capability evaluations before release, especially more detailed assessments of cyber offense, biological, chemical, and harmful manipulation capabilities that could be misused.
- Remove high-risk cyber offense, biological, and chemical weapons knowledge from training data, or use machine unlearning in post-training to remove it from model parameters.
- If the Safety Score is low:
- We recommend strengthening safety alignment and security measures, for example through supervised fine-tuning to train refusal of harmful requests, input-output monitoring to identify and filter harmful requests and responses, chain-of-thought monitoring to detect possible deception and scheming, and adversarial training to improve defenses against jailbreak requests.
- Conduct safety evaluations before release to ensure that safety reaches an acceptable level.
- Some general risk management practices:
- Develop a risk management framework suited to your own circumstances, including clear risk thresholds, mitigation measures once thresholds are reached, and release strategies. The Frontier AI Risk Management Framework may serve as a reference.
- Improve model risk disclosure, for example by releasing a system card together with the model, to increase the transparency of safety governance.
- Check the model's Capability Score and Safety Score. If the Capability Score is high:
- If the Risk Index is low:
- No special recommendation at present. Continue tracking newly released models and stay updated on changes.
- If the Risk Index fluctuates sharply in the short term:
- Analyze whether the change is driven mainly by capability or by safety.
- If the change is driven by capability: capability gains often accompany the release of new models. If safety protections do not keep pace, the Risk Index will naturally rise in the short term. We recommend preparing safety evaluations and risk-mitigation measures before release to avoid short-term spikes caused by lagging safety scores.
- If the change is driven by safety:
- If the Safety Score rises substantially: analyze the reasons, such as whether new safety measures were introduced, and share best practices with the field where appropriate.
- If the Safety Score drops substantially: identify the cause, determine whether it was expected, and, if it was unintended, fix the issue quickly and establish a robust testing process to avoid similar regressions in the future.
Concordia AI can provide frontier risk management consulting and safety evaluation services for model developers. For collaboration inquiries, please contact risk-monitor@concordia-ai.com.
For AI Safety Researchers
Based on this quarter's monitoring results, we offer the following recommendations to AI safety researchers:
- For researchers working on risk assessment:
- Explore more effective capability-elicitation methods, such as better agent frameworks and inference-time scaling, to more accurately assess models' upper-bound capabilities.
- Explore more effective attack methods, such as new jailbreak or injection methods, to more accurately assess models' lower-bound safety.
- Explore more precise ways to assess real-world risk, for example by building new threat models and designing targeted benchmarks for each relevant stage.
- Given the widespread use of AI agents, explore risk-assessment methods specifically for agentic systems.
- For researchers working on risk mitigation:
- Explore more effective approaches to safety hardening and dangerous-capability removal while preserving as much useful capability as possible.
- Since open-weight models are easier to maliciously fine-tune, explore risk-mitigation approaches tailored to open-weight models.
- Given the widespread use of AI agents, explore risk-mitigation approaches specifically for agentic systems.
These are also key future research directions for Concordia AI. We welcome collaboration with peers across the field. For collaboration inquiries, please contact risk-monitor@concordia-ai.com.
For Policymakers
Based on this quarter's monitoring results, we identify the following early warning signals:
- Cyber misuse risk: Multiple signals suggest that cyber misuse risk is rising:
- In the cyber offense domain, the Risk Index rebounded this quarter, indicating that model capabilities improved faster than model safety.
- Models reached a score of 80 on cyber CTF tasks for the first time, signaling a breakthrough in their ability to carry out long-horizon cyberattack tasks.
- This quarter, OpenAI raised the cyber risk rating of one of its models from Medium to High for the first time, namely GPT-5.4.
- The Claude Mythos Preview model, disclosed on April 7, 2026, could autonomously discover thousands of high-severity zero-day vulnerabilities and substantially outperformed Claude Opus 4.6 on Anthropic's internal cyber evaluations. Although we did not test Claude Mythos Preview, Anthropic's internal results suggest that the real cyberattack risk we face may be significantly greater than what is reflected in this report.
- Loss-of-control risk: We observe growing evidence that loss-of-control risk is increasing:
- Over the past three quarters, the average Risk Index for frontier models in the loss-of-control domain has risen continuously, with a cumulative increase of 51%.
- Frontier models already possess some self-replication and self-improvement capability, along with relatively high situational awareness.
- The Claude Mythos Preview system card reports that in internal testing, the model successfully escaped from a secure sandbox and posted technical information about the exploit to an external website. This incident suggests that AI loss-of-control is no longer merely science fiction, but has become a real possibility.
We recommend that policymakers pay close attention to the warning signals in cyber offense and loss-of-control and strengthen related regulatory requirements, such as requiring model developers to evaluate cyberattack and loss-of-control risks before releasing models and to implement necessary risk-mitigation measures. Different governance approaches may be needed for different risks, taking into account factors such as capability level, safety level, and distribution mode, whether open-weight or proprietary.
Appendix
For detailed implementation details, representative cases, and information-hazard disclosure trade-offs for the benchmarks used in this monitoring round, see here.