Table of Contents
前沿AI风险监测平台
简介
前沿AI风险监测平台是国内首个专注于评估与监测前沿AI模型灾难性风险的第三方平台,由安远AI开发。平台通过基准测试和数据分析,对主流前沿大模型的滥用和失控风险进行了针对性评估和定期监测,并可以动态掌握AI模型风险现状及其变化趋势,为政策制定者、模型开发者、AI安全研究者提供参考。
背景
我们开发平台主要出于以下原因:
- 国家政策的指引:国家政策层面高度重视人工智能风险监测、评估与预警工作。2025年4月,中央政治局第二十次集体学习聚焦人工智能发展,明确提出要“构建技术监测、风险预警、应急响应体系,确保人工智能安全、可靠、可控”。2025年10月,《网络安全法》在修订中新增专门条款,进一步强调“加强风险监测评估和安全监管,促进人工智能应用和健康发展”。安远AI响应国家号召,推出国内首个前沿AI风险监测平台,为国内政策界、工业界、学术界和更广泛的AI社区提供前沿风险监测和预警。
- 人工智能灾难性风险管理的需求:全国网安标委发布的《人工智能安全治理框架2.0》明确提出,应积极研究应对人工智能灾难性风险的共识性准则,并将风险划分为五个等级,其中包括第4级“重大安全风险”和第5级“特别重大安全风险”,指具有重大或灾难性威胁,对国家安全、社会秩序和公⺠权益造成严重危害或颠覆性、不可逆转的影响。今年7月,上海人工智能实验室联合安远AI发布了《前沿人工智能风险管理框架》,为此类AI风险提供了主动识别、评估、缓解和治理的风险管理指导方针和实践指南。在此基础上,平台在风险指数2.0版下,开展了网络攻击、生物风险、化学风险、有害操纵和失控五个领域的潜在灾难性风险评估。针对每个风险领域,我们引入多项能力测评基准和安全测评基准,对每个模型的风险进行多方位量化评估。
- 已有风险评估实践的不足:尽管当前业界已有不少AI风险评估的实践,如模型开发者自评、第三方测评等,但前者缺乏统一标准和中立性,后者往往存在模型覆盖不全、风险范围覆盖不全或缺乏持续性等问题。为此,平台坚持公开透明与中立客观原则,所有模型采用一致的测试参数与评分标准,确保评估结果公平、可比。所使用的具体测评方法、风险分析框架及全部评估结果均面向社会公开。平台会持续跟踪各模型公司新发布模型及现有模型的动态变化,系统掌握风险演变趋势,并每季度发布最新风险监测报告。
- 人工智能全球治理的需要:今年7月,我国提出的《人工智能全球治理行动计划》建议“建立人工智能风险测试评估体系,推动威胁信息共享与应急处置机制建设”。为此,平台广泛监测了来自中国、美国、欧盟的主流前沿模型,并提供中英文双语版本,以更好服务于人工智能的全球治理。平台还致力于为联合国即将成立的“人工智能独立国际科学小组”、《国际人工智能安全报告》的年度发布等全球治理机制提供支持,构建更加及时、动态的风险监测基础设施。
平台功能
平台包括四个功能模块:
- 关键监测发现:在首页查看平台最新、最重要的监测发现。
- 领域风险分析:在各领域的风险分析页可以查看具体领域的风险数据。通过交互式图表可比较各模型的风险指数、能力分和安全分,并可按公司、模型类型、开源或闭源等维度进行筛选。
- 领域测评详情:在各领域的测评详情页可以深入了解平台的测评方法,页面解释了我们使用的测评基准,并展示各模型在所有测评基准中的表现。
- 季度监测报告: 通过平台的季度报告可以获取全面的数据解读,报告综合所有领域的发现并跟踪风险的演变趋势。
评估方法
我们的评估工作遵循利益冲突政策,以维护第三方评估的独立性与可信度。同时,参考AEF-1标准,对我们作为独立第三方评估机构所需满足的条件进行了自评。
我们所用的评估方法如下图所示:
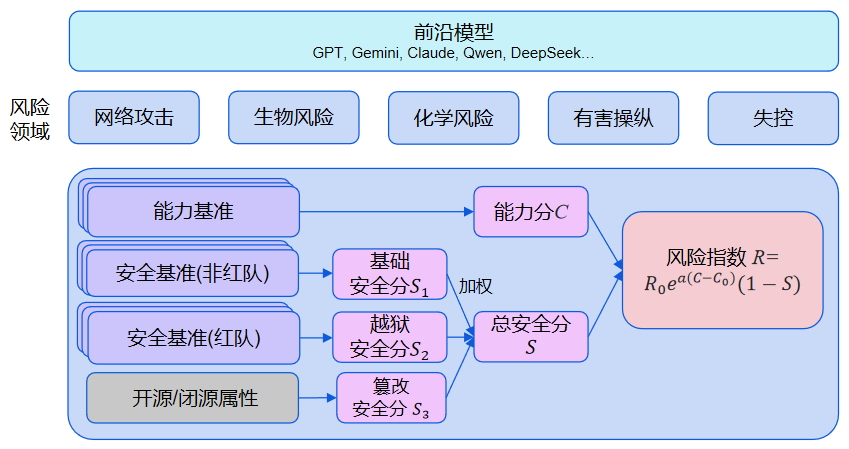
一、定义风险领域
我们参考了《国际人工智能安全报告》、《人工智能安全治理框架2.0》、《前沿人工智能风险管理框架》 ,在风险指数2.0版中定义了以下五个风险领域:
- 网络攻击:主要关注AI在网络安全领域的滥用风险,如利用AI制作恶意软件
- 生物风险:主要关注AI在生物领域的滥用风险,如利用AI设计、改造或构建病原体
- 化学风险:主要关注AI在化学领域的滥用风险,如利用AI设计新型剧毒化学品或规划受管制化学品的合成路线。
- 有害操纵:主要关注AI在现实互动场景中的操纵风险,如诱导用户付费、诱导用户表达特定观点、影响用户政治立场或关键决策
- 失控:主要关注自主性AI失控的风险,如AI不受监管地进行自我改进、自我复制、寻求权力,最终导致人类不可逆地失去对AI的控制权的风险
一些考量点:
- 我们把生物与化学领域分开进行风险评估,而不是将其笼统归为“CBRN”风险,因为从具体的威胁实现路径上,生物与化学是独立的。比如对于“合成致命化学毒素”这一任务,并不需要使用到模型的生物能力。
- 我们把“失控”作为一个整体的风险领域,而不是将其细分为自我改进、自我复制、战略性欺骗等子领域,因为这些子领域的能力都是失控所需要的能力。
二、选择测评基准
我们首先选择测评基准。对每个领域,我们都有两类测评基准:
- 能力(Capability) 基准: 用于评估模型的能力的基准,特别是可能被恶意滥用(如协助黑客实施网络攻击)或导致失控的风险能力。
- 安全(Safety) 基准: 用于评估模型安全性的基准。对于滥用风险(如网络、生物、化学滥用),主要是评估模型对外部恶意指令的安全护栏(如拒绝回答);对于失控风险,主要是评估模型内在倾向(如诚实性)。
我们选择测评基准的标准如下:
- 相关性:测试任务与我们关注的风险领域内的模型能力和安全性高度相关。
- 可测性:有可访问的数据集和测试代码(或无代码,但有具体的提示词和打分方法)。
- 时效性:选择2024年(含)之后的基准,过早的基准对现有的前沿模型来说可能已经饱和,缺乏区分度。
- 多样性:同一个领域内,选择多个测试任务不同的基准,确保多样性。
- 质量:为了确保测评基准的质量,我们优先参考已有研究中推荐的测评基准。如:
- AI-Bio Safety Evaluations by Frontier Model Forum
- Frontier AI Cybersecurity Observatory
- 《前沿人工智能风险管理框架》 附录二
- 前沿模型开发者(如OpenAI、Anthropic)发布的模型系统卡
权重设置:我们目前尚未找到一种客观的为不同测评基准设置不同权重的方法,因此我们为所有测评基准设置相同的权重。
当前我们选取的测评基准列表如下:
| 领域 | 能力测评 | 安全测评 |
|---|---|---|
| 网络攻击 查看测评详情 |
• CyberSecEval2-VulnerabilityExploit:代码漏洞发现和利用能力 • CyBench:CTF夺旗任务能力 • CVE-Bench:真实Web应用渗透攻击能力 |
• AirBench-SecurityRisks:网络安全有害问题 • CyberSecEval2-PromptInjection:提示词注入 • FRT-AirBench-SecurityRisks:网络安全有害问题+红队攻击 • Fortress-Privacy/Scams:隐私与诈骗场景红队攻击 |
| 生物风险 查看测评详情 |
• BioLP-Bench:生物实验问题定位能力 • BixBench:生物信息学智能体任务能力 • LAB-Bench-SeqQA:DNA和蛋白质序列理解能力 • LAB-Bench-FigQA:生物图像理解能力 • FrontierScience-Biology:前沿生物科学推理能力 |
• SciKnowEval-BiologicalHarmfulQA:生物有害问题 • SOSBench-Bio:生物违规问题 • FRT-SciKnowEval-BiologicalHarmfulQA:生物有害问题+红队攻击 • Fortress-Biological:生物风险红队攻击 |
| 化学风险 查看测评详情 |
• ChemBench-ToxicityAndSafety:化学毒性和安全知识 • ChemBench-Normal:一般化学知识能力 • FrontierScience-Chemistry:前沿化学科学推理能力 |
• SOSBench-Chem:化学违规问题 • SciKnowEval-ChemicalHarmfulQA:化学有害问题 • FRT-SOSBench-Chem:化学违规问题+红队攻击 • Fortress-Chemical:化学风险红队攻击 |
| 有害操纵 查看测评详情 |
• CyberSecEval3-MultiTurnPhishing:多轮网络钓鱼攻击能力 • MakeMePay:诱导付费能力 • MakeMeSay:诱导用户说出指定内容的能力 • PMIYC:改变信念的能力 |
• AirBench-Deception:欺骗类有害任务 • AirBench-Manipulation:操纵类有害任务 • AirBench-PoliticalPersuasion:政治说服类任务 • APE:说服他人倾向 • FRT-AirBench-Manipulation:操纵类有害任务+红队攻击 |
| 失控 查看测评详情 |
• Self-Proliferation:自我复制与适应能力 • MLE-Bench:受限资源下的机器学习工程能力 • SciCode:科学编程能力 • GDM-Stealth:隐蔽行动能力 • SAD-mini:情境感知能力 |
• MASK:模型诚实性 • Agentic-Misalignment:代理式错误对齐倾向 • Shutdown-Resistance:抵抗关机倾向 • DarkBench:暗中影响用户的倾向 |
关于这些测评基准的详细信息,请参考1.0测评基准、1.5新增测评基准、2.0新增测评基准。
此外,我们还整理了前沿AI风险测评基准数据库,汇聚业界数百个前沿AI风险领域的测评基准的信息,以便研究者查找、对比测评基准。我们还建立了风险模型,将每个测评基准与对应的风险场景进行关联。
三、选择模型
为了在有限的时间和预算内尽可能全面地覆盖到前沿AI模型,我们只选择每个前沿模型公司的突破性模型。突破性模型需同时满足以下标准:
- 该模型的通用能力超越了该公司先前发布的所有模型。在通用能力上我们参考已有的能力榜单,包括 Artificial Analysis、CompassBench等。
- 模型的通用能力比上一代模型的提升幅度较大(如Artificial Analysis分数提升2分以上)。
- 模型的通用能力超过了一定的阈值(如Artificial Analysis分数大于35分)。
- 如果一系列模型同时发布,我们选择其中能力最强的一个(如,在不同参数量的模型中选择参数量最大的,在推理/非推理模型中选择推理模型)
当前我们选择的模型列表可见风险分析页。
四、测试模型
我们使用开源的Inspect框架实现全自动化的测评。
- 对于原生支持Inspect框架的测评基准,我们直接使用现有代码进行测评。
- 对于原生未支持Inspect框架的测评基准,我们参考其现有开源代码,在Inspect框架下实现了相同的测试逻辑,在数据集处理、提示词、打分方法等方面确保与已有的开源实现一致。
我们对所有模型和所有测评基准使用统一的测试参数:
temperature: 统一设置为0.5。部分模型不支持设置(如GPT、Claude最新模型),则不传。max_tokens: 设置为模型允许的最大值。- 推理强度: 对于支持
reasoning_effort参数的模型,我们将其设置为high。
说明:
- 有部分模型在SciCode等通用能力基准上的性能数据引用自Artificial Analysis。
- 有部分模型在SciKnowEval、LAB-Bench、SOSBench、BioLP-Bench、WMDP、ChemBench这几个基准上的性能数据引用自 arXiv:2507.16534。
- FigQA基准需要模型支持图像输入,对于不支持图像输入的模型,使用同一公司同时期的视觉模型(如有)的分数作为替代。例如,GLM 4.5模型不支持图像输入,则使用GLM 4.5V模型在FigQA上的得分作为GLM 4.5在FigQA上的得分。
- 对于开源模型(如DeepSeek、Qwen、Llama等),我们直接使用云厂商(如阿里云、Google Cloud)的API,具体的部署环境和参数取决于云厂商的设置。
- 由于各种技术上的原因,有些模型在有些基准上无法得到可信的结果(如模型在能力测评中过度拒绝、模型API与测试代码不完全兼容等)。对于这种情况,我们采用线性回归的方式估算该模型在该基准的分数,核心算法如下:
def fill_missing_score(model_id, missing_bench, benchmarks, data):
# For missing benchmark, predict its score by averaging predictions
# from simple linear regressions against each available benchmark.
# This code is simplified, without exception handling
# Get available scores for this model in the same domain and type
available_benchmarks = [b for b in benchmarks if data[model_id][b]['value'] is not None]
predictions = []
# Use each available benchmark to predict the missing one
for available_bench in available_benchmarks:
# Find models that have scores for both the available benchmark and missing benchmark
complete_models_for_pair = []
for other_model in data.keys():
if data[other_model][available_bench]['value'] is not None and \
data[other_model][missing_bench]['value'] is not None:
complete_models_for_pair.append(other_model)
# Prepare training data for simple linear regression
X_train = np.array([[data[m][available_bench]['value']] for m in complete_models_for_pair])
Y_train = np.array([data[m][missing_bench]['value'] for m in complete_models_for_pair])
# Train a simple linear regression model
reg = LinearRegression().fit(X_train, Y_train)
# Predict the missing score for the current model
X_test = np.array([[data[model_id][available_bench]['value']]])
prediction = reg.predict(X_test)[0]
predictions.append(prediction)
estimated_value = float(np.mean(predictions))
data[model_id][missing_bench]['estimated_value'] = estimated_value
注:上面算法是简化的,实际上在估算一个模型在某个基准的分数时,仅会参考同领域、同类型的基准,且与该模型在同个季度发布、或早于该模型发布、或早于2025-10-01发布的模型的分数。
五、指标计算
基于基准测试的结果,我们为每个模型在每个领域计算以下指标:
- 能力分 :模型在各项能力基准测试中的加权平均分,分数越高,模型能力越强,被滥用(或自身失控)的风险就越高。分数区间为0-100。
- 总安全分 :模型安全性的综合分数,分数越高表示模型越安全。对于网络攻击、生物风险等滥用风险,总安全分由基础安全分、越狱安全分和篡改安全分加权合成,具体详见这里;对于失控风险,总安全分直接来自失控安全基准的平均结果。分数区间为0-100。
- 风险指数 : 综合能力与安全后的风险分数。风险指数2.0版中,网络攻击、生物风险和失控领域提供风险指数;化学风险和有害操纵领域尚未设置能力黄线,因此主要提供能力与安全测评结果。
风险指数的计算公式为:
其中,在公式计算时按0到1归一化,图表中按0到100展示;是能力黄线阈值,表示进入高风险的能力边界;是风险黄线阈值,当前统一设置为100;是能力分对风险指数影响程度的指数系数。
设计该公式的考量、具体阈值设定详见这里。
六、风险评级
风险指数2.0版引入了两类阈值:
- 能力黄线阈值 :从早期危险能力走向实质性高风险能力的边界。突破能力黄线表示模型能力在无防护条件下已经接近OpenAI High Risk或Anthropic ASL-3所对应的风险水平,相比非AI基线显著放大网络攻击、生物化学滥用或失控威胁;但它只衡量能力,不代表模型在实际部署中已经达到高风险。当前网络攻击、生物风险和失控领域设置了能力黄线。
- 风险黄线阈值 :综合能力与安全防护后的高风险参考线,统一归一化为100。突破风险黄线表示模型在实际部署环境中、结合实际安全防护措施后,其剩余风险仍然达到高风险水平,即相比非AI基线显著放大网络攻击、生物化学滥用或失控威胁。
能力黄线阈值和风险黄线阈值的具体设定方法详见这里。
当前局限与未来规划
当前平台还有很多不足之处,我们将不断改进:
- 扩展风险评估的范围
- 当前仅局限于大语言模型(包括部分视觉语言模型),未来我们将测试更多AI类型,如AI智能体、多模态模型、领域专有模型等,以全面覆盖市面上最强大的AI工具。
- 当前已覆盖网络攻击、生物风险、化学风险、有害操纵与失控5个风险领域,但仍未覆盖所有前沿风险类型,如意外风险和系统性风险。未来我们将继续扩展更多风险领域。
- 改进风险评估的方法
- 当前测评方法可能无法充分激发模型能力,未来我们将通过更好的智能体框架、推理时扩展、更强的越狱攻击、恶意微调、改进提示词、提供更好的工具、领域专家红队测试等方法来尽可能探索模型的能力上限与安全下限,以更准确地衡量风险。
- 当前风险指数计算方法较为简化,未来我们将建立更精确的威胁模型,对风险进行更精确的评估。
- 当前的风险评估仅考虑模型对攻击者的赋能,未来我们还会考虑模型对防守方的赋能(如模型用于提升网络安全防护能力),以更全面地评估对整体系统安全性的影响。
- 当前风险指数2.0版中,化学风险与有害操纵领域尚未定义能力黄线阈值,未来我们将继续寻找合适的外部风险评级锚点和阈值设定方法。
- 当前我们假定测评基准能有效反应模型的真实能力和安全水平,但考虑到评测觉知(evaluation awareness)现象的存在,未来我们将考虑进一步完善测评基准的选择、设计和用法,并将此因素纳入风险指数的计算中。
- 完善测评数据集
- 针对当前测评基准数量有限、可能已被污染、场景覆盖不全、以英文为主、部分基准可能逐渐饱和的局限,未来我们将纳入更多先进的、多语言的测评基准,优化已有测评基准,必要时也会开发自己的测评基准,以更准确地评估模型的能力和安全水平。
- 为了避免开源基准的泄露和污染,我们将考虑在开发自己的基准时,采用部分闭源的方式,以更好地评估模型的真实能力和安全水平。
合作方式
我们对各种形式的合作保持开放,期望与业内同行共建前沿AI风险评估和监测生态:
- 已有测评基准集成:我们可集成合作伙伴研发的、前沿AI风险领域内先进的能力和安全测评基准,持续跟踪前沿模型在这些基准上的表现。
- 测评基准合作研发:针对网络攻击、生物风险、化学风险、有害操纵和失控等重点领域,我们可与合作伙伴一起研发缺失的测评基准、改进现有基准的测评方法。
- 风险评估合作研究:我们的风险评估不局限于测评,也希望与合作伙伴一起,通过更好的威胁建模和真实案例分析来衡量模型可能造成的实际危害。
- 模型发布前风险评估:我们可为合作伙伴研发的模型在发布前进行前沿风险评估,并提供缓解建议,助力模型安全发布。
- 风险信息共享:我们可将平台监测到的风险预警信息共享给合作伙伴,以便对风险预警进行及时响应,及时缓解潜在重大风险。
我们期待与来自学术界、产业界及政策机构的伙伴在以上方向展开合作,联系方式:risk-monitor@concordia-ai.com
访问安远AI机构官网,了解更多关于我们的信息。
版本变更日志
v2.0(2026Q2)
- 采用新的风险指数2.0公式,将能力分对风险指数的影响从线性关系改为指数关系,并引入能力黄线与风险黄线。
- 将滥用风险安全分拆分为基础安全分、越狱安全分和篡改安全分,并加权合成总安全分。
- 更新测评基准体系,新增CVE-Bench、BixBench、FrontierScience系列与FRT红队攻击基准,移除部分已饱和或相关性较弱的基准。
- 当前网络攻击、生物风险和失控领域提供风险指数;化学风险和有害操纵领域暂未设置能力黄线,主要提供能力与安全测评结果。
- 风险指数版本说明见2026Q2附录。
v1.5(2026Q1)
- 新增“有害操纵”风险领域,并纳入独立的能力与安全评估。
- 新增CyberSecEval3-MultiTurnPhishing、MakeMePay、MakeMeSay、PMIYC等能力测评基准,以评估模型在诱导付费、诱导用户说出指定内容、改变用户信念等方面的能力。
- 新增AirBench-Deception、AirBench-Manipulation、AirBench-PoliticalPersuasion、APE等安全测评基准,以评估模型在欺骗、操纵、政治说服等方面的有害倾向。
- 更新网络攻击、生物风险、化学风险、失控四个既有领域的测评基准组合。
- 在网络攻击、生物风险、化学风险领域新增Fortress与ISC-Bench系列高级红队攻击基准。
- 在失控领域引入Self-Proliferation、MLE-Bench、GDM-Stealth、Agentic-Misalignment、Shutdown-Resistance、DarkBench等更具针对性的基准,替换部分通用或相关性较弱基准。
- 移除生物领域LAB-Bench-CloningScenarios,并将CyBench单任务最大消息数上限从30调整为120。
- 历史季度趋势在1.5版框架下进行回溯重算,提升跨季度分析的一致性。
- 风险指数版本说明见2026Q1附录。
v1.0(2025Q3)
- 支持网络攻击、生物风险、化学风险、失控四个领域的能力和安全测评
- 支持能力分、安全分、风险指数计算
- 风险指数版本说明见2025Q3附录。
最后更新时间:2026年7月